

Что такое веб-архив
Веб-архив — это специализированная цифровая библиотека, которая систематически собирает, хранит и предоставляет доступ к историческим копиям веб-страниц и сайтов. По своей сути, это своеобразная "машина времени" для интернета, позволяющая заглянуть в прошлое цифрового пространства и увидеть, как выглядели сайты неделю, месяц или десятилетие назад.
Технически веб-архив представляет собой распределенную систему, которая с определенной периодичностью сканирует веб-страницы, сохраняя их HTML-код, графические элементы, стили CSS, скрипты JavaScript и другие ресурсы. Эти "снимки" (снапшоты) сохраняются вместе с метаданными: точной датой и временем сохранения, URL-адресом, техническими характеристиками.
Ключевые характеристики веб-архивов:
-
Хронологическая организация — все сохраненные версии упорядочены по дате
-
Неизменность — однажды сохраненная версия остается неизменной
-
Ссылочная целостность — сохранение внутренних и внешних ссылок
-
Масштабируемость — хранение петабайтов информации
Самый известный и масштабный проект в этой области — Internet Archive's Wayback Machine, запущенный в 2001 году и содержащий более 800 миллиардов веб-страниц. Однако существуют и национальные веб-архивы (в Великобритании, Франции, скандинавских странах), корпоративные и специализированные архивы.
Важное отличие веб-архива от обычного резервного копирования сайта заключается в его публичности и систематичности. Если бэкапы делаются для конкретного сайта и хранятся приватно, то веб-архивы собирают информацию со всего интернета и предоставляют к ней публичный доступ.
Зачем нужен web archive и как его можно использовать
Веб-архив — это не просто цифровой курьез, а мощный инструмент с множеством практических применений в различных сферах деятельности.
Научные исследования и исторический анализ
Для ученых, историков и социологов веб-архивы представляют неоценимую ценность как источник информации о цифровой эволюции общества. С их помощью можно:
-
Изучать развитие интернет-технологий и веб-дизайна
-
Анализировать изменения в медиа-пространстве
-
Прослеживать эволюцию общественного мнения по различным вопросам
-
Исследовать исторические события через призму их освещения в интернете
Например, изучение архивных версий новостных сайтов во время важных политических событий позволяет понять, как менялась подача информации, какие нарративы преобладали в разные периоды.
Юридические и доказательные цели
В юридической практике веб-архивы часто используются как источник доказательств:
-
Установление факта существования контента на определенную дату
-
Фиксация нарушений авторских прав
-
Документирование случаев клеветы или диффамации
-
Подтверждение условий оферт или публичных договоров
В некоторых странах архивированные веб-страницы признаются в качестве доказательств в суде при условии соблюдения процедуры нотариального заверения цифровых копий.
Восстановление утерянной информации
Для веб-мастеров и владельцев сайтов веб-архив становится спасательным кругом в ситуациях:
-
Потери данных при сбое хостинга или неудачном обновлении
-
Необходимости восстановления удаленного контента
-
Возврата старого дизайна или функционала
-
Поиска утерянных медиафайлов (изображений, документов)
Многие разработчики используют Wayback Machine для восстановления фрагментов кода, текстовых материалов или графических элементов, которые были случайно удалены или перезаписаны.
SEO-анализ и конкурентная разведка
В digital-маркетинге веб-архивы применяются для:
-
Анализа истории изменений сайтов конкурентов
-
Изучения эволюции SEO-стратегий
-
Выявления паттернов успешного и неуспешного контента
-
Восстановления истории ссылочной массы
Маркетологи могут проследить, какие изменения на сайте конкурента привели к росту или падению позиций, и адаптировать успешные стратегии для своих проектов.
Образовательные цели
Для студентов и преподавателей веб-архивы служат:
-
Источником примеров для изучения веб-разработки
-
Материалом для анализа эволюции цифровых коммуникаций
-
Базой для практических заданий по информационному поиску
-
Иллюстративным материалом для курсов по истории интернета
Сохранение цифрового культурного наследия
Веб-архивы выполняют важнейшую культурологическую функцию — сохранение цифрового наследия для будущих поколений. Они архивируют:
-
Сайты культурных учреждений (музеев, библиотек, театров)
-
Онлайн-публикации литературных произведений
-
Цифровое искусство и медиа-эксперименты
-
Блоги и персональные страницы известных личностей
Без систематической архивации огромные пласты цифровой культуры оказались бы безвозвратно утерянными из-за недолговечности веб-хостингов, закрытия проектов или технических сбоев.
Как просмотреть старые версии сайтов на Wayback Machine
Wayback Machine от Internet Archive — наиболее популярный и доступный инструмент для просмотра архивных версий сайтов. Работа с ним не требует специальных навыков, но знание некоторых приемов позволяет извлекать максимальную пользу.
Базовый поиск по URL
Самый простой способ — прямой ввод адреса сайта в поисковую строку на сайте archive.org/web.
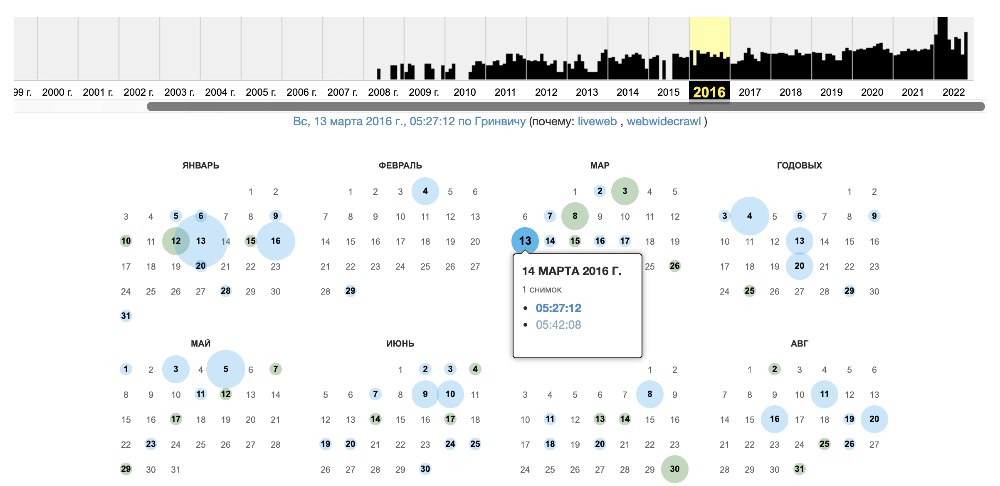
После ввода URL система показывает:
-
Временную шкалу с годами, за которые есть сохраненные копии
-
Количество сохранений для каждого года
-
Календарную визуализацию с отметками дней, когда делались снимки
На календаре разными цветами обозначаются дни с разной интенсивностью архивации: синие кружки указывают на успешные сохранения, красные — на ошибки или недоступность сайта в тот момент.
Навигация по сохраненным версиям
После выбора конкретной даты из архива загружается сохраненная версия сайта. Важные особенности навигации:
-
Все ссылки на архивированной странице ведут на другие архивированные страницы с максимально близкой датой сохранения
-
Вверху страницы появляется панель Wayback Machine с информацией о дате сохранения и возможностью переключения между соседними по времени версиями
-
Некоторые динамические элементы (формы, скрипты) могут не работать, так как архивируется статическое состояние страницы
Расширенные возможности поиска
Для профессиональной работы с архивами полезно знать о дополнительных функциях:
Поиск по ключевым словам в тексте страниц — доступен через специальный интерфейс, позволяет находить страницы, содержащие определенные фразы на момент архивации
API доступ — программисты могут интегрировать поиск по архиву в свои приложения через официальное API
Просмотр специфических типов файлов — можно искать отдельно архивированные изображения, PDF-документы, видеофайлы
Сравнение версий — некоторые сторонние инструменты позволяют визуально сравнивать разные версии одной страницы
Ограничения и проблемы при просмотре
При работе с Wayback Machine важно учитывать технические ограничения:
-
Не все страницы архивируются полностью (могут отсутствовать некоторые ресурсы)
-
JavaScript-зависимый контент часто отображается некорректно
-
Медиафайлы большого размера могут не сохраняться
-
Страницы с ограничением через robots.txt или noarchive-метатеги не архивируются
-
Для некоторых сайтов может быть недостаточно исторических данных
Мобильный доступ и расширения браузера
Wayback Machine доступен не только через веб-интерфейс, но и через:
-
Мобильные приложения для iOS и Android
-
Браузерные расширения, позволяющие быстро проверять архивные версии текущей страницы
-
Интеграции с поисковыми системами через специальные операторы
Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
Сохранение страницы в Wayback Machine
Любой пользователь может добавить текущую версию страницы в архив. Для этого:
Перейдите на страницу archive.org/web
Введите URL страницы, которую хотите сохранить
Нажмите "SAVE PAGE" — система сделает снимок страницы и сохранит его в архиве
Этот процесс может занять от нескольких секунд до нескольких минут в зависимости от сложности страницы и нагрузки на серверы Internet Archive.
Автоматическая архивация через Save Page Now
Для регулярного архивирования можно использовать API Save Page Now, который позволяет:
-
Интегрировать архивацию в процессы публикации контента
-
Настроить автоматическое сохранение при обновлении сайта
-
Создавать собственные инструменты массовой архивации
Использование метатегов для управления архивацией
Владельцы сайтов могут контролировать процесс архивации через специальные метатеги и директивы:
html
<!-- Запрет архивации всей страницы --> <meta name="robots" content="noarchive"> <!-- Разрешение архивации, но запрет на индексацию поисковиками --> <meta name="robots" content="noindex, archive"> <!-- Указание даты, после которой страницу не следует архивировать --> <meta name="archive-after" content="2025-12-31">
robots.txt и архивация
Файл robots.txt также влияет на архивацию:
-
Директива User-agent: ia_archiver управляет поведением робота Wayback Machine
-
Запрет через robots.txt обычно соблюдается, но есть исключения
-
Изменения в robots.txt не влияют на уже архивированные версии
Удаление контента из архива
Internet Archive предусматривает процедуру удаления контента по запросу правообладателей:
Необходимо отправить официальный запрос с обоснованием
Указываются конкретные URL и даты сохранения
Процесс может занять несколько недель
Удаляются только конкретные снимки, а не все упоминания сайта
Программа партнерства для организаций
Крупные организации могут участвовать в программе партнерства, которая предоставляет:
-
Приоритетную архивацию важных ресурсов
-
Расширенные возможности экспорта данных
-
Техническую поддержку
-
Возможность создания специализированных коллекций
Локальные решения для веб-архивации
Помимо использования публичных сервисов, организации могут развертывать собственные системы архивации:
-
OpenWayback — открытое ПО для создания веб-архивов

-
Heritrix — масштабируемый веб-краулер для архивации
-
WARC стандарт — формат хранения архивированного контента
Эти решения позволяют создавать специализированные архивы для внутренних нужд, исследований или коммерческого использования.
Этика и ответственность при архивации
При добавлении контента в веб-архив важно учитывать:
-
Авторские права на архивируемые материалы
-
Конфиденциальность пользовательских данных
-
Национальное законодательство об архивации
-
Этические аспекты сохранения цифрового наследия
Уникальный контент из веб-архива
Исследование цифровых артефактов
Веб-архивы содержат бесценные коллекции цифровых артефактов, которые больше не существуют в оригинальном виде:
-
Первый сайт в истории — info.cern.ch, созданный Тимом Бернерсом-Ли в 1991 году
-
Ранние версии популярных сервисов — Google 1998 года, Amazon 1995 года, eBay 1995 года
-
Закрытые социальные сети — первые версии Friendster, MySpace, Google+
-
Исторические новостные сайты в момент освещения ключевых событий
Эти материалы представляют интерес не только как исторические курьезы, но и как объекты серьезного исследования эволюции интернет-технологий, дизайна и пользовательских интерфейсов.
Восстановление утраченных цифровых произведений
Благодаря веб-архивам удалось сохранить:
-
Цифровое искусство, созданное с использованием устаревших технологий (Flash-анимация, Java-апплеты)
-
Литературные произведения, опубликованные только онлайн и не изданные на бумаге
-
Научные статьи и исследования, размещенные на ныне несуществующих ресурсах
-
Блогосферу раннего интернета с уникальными свидетельствами эпохи
Анализ эволюции веб-стандартов
Изучая архивные версии сайтов, можно проследить:
-
Переход от табличной верстки к блочной
-
Эволюцию подходов к responsive design
-
Изменения в использовании технологий (от Flash к HTML5)
-
Развитие веб-типографики и цветовых схем
Сохранение цифровых свидетельств исторических событий
Wayback Machine архивирует реакцию интернет-сообщества на важные события:
-
Выборы и политические процессы разных стран
-
Кризисные ситуации (пандемии, природные катастрофы)
-
Культурные и спортивные мероприятия мирового масштаба
-
Технологические прорывы и их освещение в медиа
Эти цифровые свидетельства позволяют проводить сравнительный анализ подачи информации, изучать формирование общественного мнения, анализировать риторику разных медиа.
Генеалогические исследования
Веб-архивы становятся инструментом для генеалогов и биографов:
-
Поиск информации о людях через архивные версии социальных сетей
-
Изучение профессиональных сайтов и портфолио
-
Восстановление истории организаций и сообществ
-
Нахождение публикаций и упоминаний в СМИ
Образовательные коллекции и выставки
На основе материалов веб-архивов создаются:
-
Тематические коллекции по истории интернета
-
Виртуальные выставки цифрового искусства
-
Учебные материалы для курсов по digital-грамотности
-
Исследовательские проекты по digital humanities
Правовые прецеденты и их цифровое отражение
Архивы сохраняют контент, который стал предметом судебных разбирательств:
-
Дела о нарушении авторских прав
-
Споры о доменных именах
-
Иски о защите чести и достоинства
-
Прецеденты в области интернет-регулирования
Экономическая история в цифровом отражении
Через веб-архивы можно изучать:
-
Развитие электронной коммерции
-
Эволюцию бизнес-моделей в интернете
-
История цен и ассортимента онлайн-магазинов
-
Рекламные стратегии разных периодов
Техническая археология и реверс-инжиниринг
Для разработчиков архивы предоставляют возможности:
-
Изучения работы устаревших веб-технологий
-
Восстановления принципов работы legacy-систем
-
Анализа безопасности исторических версий ПО
-
Понимания эволюции веб-стандартов и браузеров
Культурная антропология цифровой эпохи
Веб-архивы фиксируют изменения в:
-
Языке интернет-коммуникации (мемы, аббревиатуры, неологизмы)
-
Цифровом этикете и нормах поведения онлайн
-
Визуальной культуре веб-пространства
-
Цифровых субкультурах и сообществах
Прогностические исследования на основе исторических данных
Анализируя архивные данные, можно:
-
Выявлять закономерности в развитии технологий
-
Прогнозировать тренды на основе исторических аналогов
-
Понимать цикличность цифровых явлений
-
Строить модели эволюции онлайн-поведения
Ключевые выводы:
Веб-архивы представляют собой не просто технический инструмент для сохранения копий сайтов, а сложную экосистему, играющую crucial роль в сохранении цифрового наследия человечества. От научных исследований до практического восстановления утерянных данных, от юридических доказательств до культурологического анализа — применение веб-архивов продолжает расширяться по мере осознания ценности цифровой истории.
Развитие технологий веб-архивации, появление новых форматов хранения и методов анализа архивных данных открывают перспективы для более глубокого понимания цифровой эволюции общества. В условиях постоянно ускоряющегося обновления интернет-контента систематическая архивация становится не просто полезной практикой, а необходимостью для сохранения памяти цифровой цивилизации.

